
Self-Supervised Learning
Self-Supervised Learning aims to provide backbone of the model for classification tasks.
Large Batch
(e.g. SImclr,CLIP) They needs large batch sizes since that’s the way it could have sufficient collection of negative samples.
Image Augmentation
Contrastive learning tries to augment images by adding noises, but still keeps the features of the images.
Linear Evaluation
Margin Triplet Loss Function
Under-Clustering
Model has insufficient negative pairs of datasets to differentiate actual object classes.
Over-Clustering
Model has excessive number of negative pairs datasets so that it is difficult to differentiate object classes.
nce loss Function
Pretext Task
The task that model can answer what tasks have been performed in the images such as making images flipped, zigsaw puzzle.
Contrastive Self-Supervised Learning
- Self-Supervised Learning
- What is Contrastive Self Supervised Learning
- SimCLR
- Difference between Contrastive Self-Supervised Learning and Non-Contrastive Self-Supervised Learning
Self-Supervised Learning
It is training algorithms with datasets that have no labeled data. It uses the structure of the data, for example, sentence that has hidden word in it is used as input data and model predicts the hidden word. Without using the labels of the data, structure of the data itself is used for self-supervised learning model to be trained. On other words, the structure of the input datasets is used as a supervisory signal. Since Self-Supervised Learning uses feedback signal from the data, it is not unsupervised learning, and actually it is more supervised than standard supervised learning.
The reason of Self-Supervised Learning is hard to used in Computer Vision than NLP
It is easy to associate score for the prediction score to all possible words, for example, high score for the cheetah and lion and low score for the cat or fish.
- But it is not sure to efficiently represent uncertainty when model predict missing frames in a video or missing patches in an image. There are infinite cases for each frame and patches and it is extremely difficult to associate scores to them.
- In order to address the issue, SwAV are starting to beat accuracy record in vision tasks.
-
In typical machine learning, softmax is used to represent the distribution of the probability for each possible case. However, there are infinite cases from missing images or missing frame, so it is impossible to represent from continuous spaces.
- Downstream task
- The task that I actually want to solve by utilizing pertained model
Joint embedding
Assuming there are images X and Y, that are slightly different versions of the same image. The model is trained to lower the energy from the outputs of the model. So if the X and Y are different versions of the same image, then the model will produce the similar embedding vectors for the two images.
Contrastive energy-based SSL
It is based on simple idea of constructing X and Y that are not compatible, and adjusting the parameters of the model so that the corresponding output energy is large.
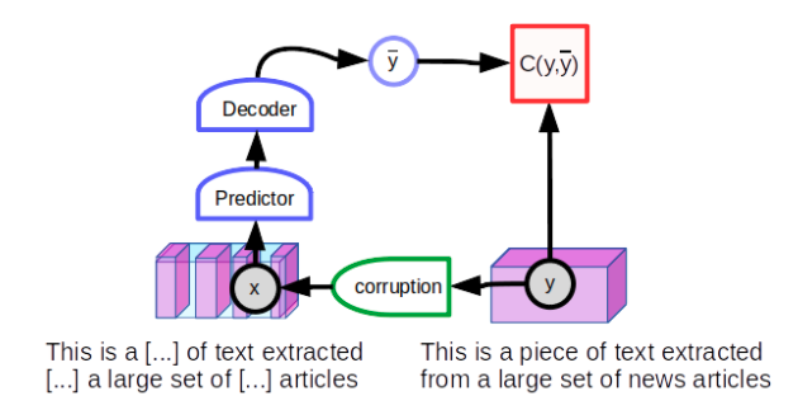
“An uncorrupted text will be reconstructed as itself (low reconstruction error), while a corrupted text will be reconstructed as an uncorrupted version of itself (large reconstruction error). If one interprets the reconstruction error as an energy, it will have the desired property: low energy for “clean” text and higher energy for “corrupted” text.”
Predictive architecture of this type can only produce single output prediction for a given input. Model must be able to produce multiple possible outcomes, the prediction is not a single set of words but a series of scores for every word in the vocabulary for each missing word location.
However, we cannot use this trick for images because we cannot enumerate all possible images.
Leave a comment